原创 朱欣怡 集智俱乐部
导语
近期发表在 Nature 子刊 Communications Physics 上的一项最新研究提出一种新的社团检测算法——局域搜索算法(Local Search)。该方法在多个标准基准测试中表现优异,尤其是在检测社团层次结构方面。与传统的社团检测方法相比,LS算法在保持高准确性的同时,显著提高了效率,例如在三十万节点、一百万条连边的大规模PubMed网络上速度比现有经典的最快算法Louvain快近五倍!
研究领域:复杂网络,社团检测,城市流动性网络,聚类分析
朱欣怡 | 解读作者
李睿琪 | 审校
论文题目:Local dominance unveils clusters in networks
论文链接:https://www.nature.com/articles/s42005-024-01635-4
论文作者:Dingyi Shi(史定一), Fan Shang(尚璠), Bingsheng Chen(陈炳生), Paul Expert, Linyuan Lü(吕琳媛), H. Eugene Stanley, Renaud Lambiotte, Tim S. Evans & Ruiqi Li(李睿琪)
比利时似乎是典型的双文化社会:59%的公民是说荷兰语的弗拉芒人,40%的公民是说法语的瓦隆人。随着全世界的多民族国家纷纷分裂,我们不禁要问:比利时如何促进了两个民族自1830年以来的和平共处?这是不是一个无论弗拉芒人还是瓦隆人都同样紧紧相连的社会?抑或是在这个国家里存在彼此联系不多的两个小国家?
——《巴拉巴西网络科学》
1. 网络社会检测
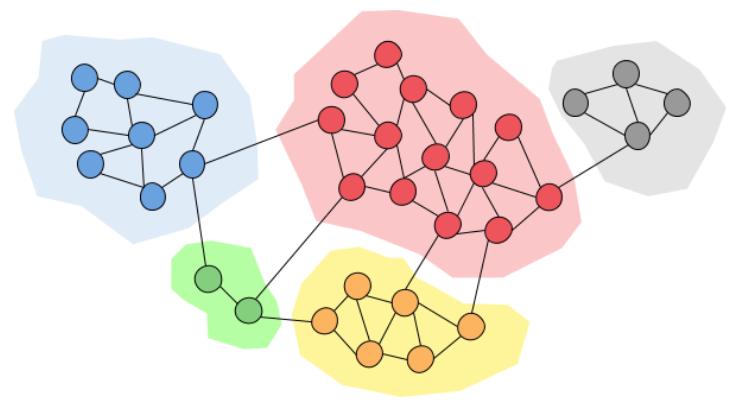
在网络科学中,如果一组节点内部链接紧密,外部链接稀疏,那么我们称这组节点为一个团簇(cluster)或社团(community)。社团和团簇的概念在社会网络、生物网络等多个领域都有广泛的应用。在社交网络中,团簇结构代表了社交网络中的自然分组,反映了人们基于共同兴趣、目标或背景形成的联系。例如,一个公司的员工更可能与本公司的同事交流,而不是与其他公司的雇员。因此,工作场所是社交网络中紧密相连的社团。在生物网络中,社团为理解特定生物功能如何在细胞网络中编码发挥了重要作用。
社团检测(Community Detection)是网络科学中的一个关键任务,旨在找出网络中的集群,通过识别和划分网络中的节点,使得相同社团内的节点之间存在较为密集的连接,而不同社团之间的连接相对较少。在社交网络中,社团检测方法能够帮助我们识别社交网络中的朋友圈或专业群体;在生物网络中,社团检测能够帮助我们识别蛋白质之间相互作用的网络,发现参与相同生物过程或疾病机制的分子团;在信息网络中,社团检测能够聚合内容,帮助用户发现和订阅特定主题或兴趣相关的信息源。在市场和经济网络中,社团检测可以细分市场,识别消费者群体的特征和需求,为定制化的营销策略提供依据。
在网络中进行社团检测是一项困难的计算任务。因为网络内的社团数量通常是未知的,并且社团的规模和密度通常不相等,早期学者通常在计算出节点间的某种距离矩阵之后,应用经典的层次聚类算法或其他向量数据聚类的方法,但这种方式对于如何定义节点间的距离非常敏感,而且聚类结构往往也不尽如人意。之后网络科学家们从拓扑结构出发,提出了多类社团检测方法,如最小切割法、Girvan-Newman算法、模块度最大化方法(如Louvain算法)、谱分析算法、基于动力学的算法(如LPA、Infomap、CFinder)等等。
但是诚如中指出“所有这些方法都依赖于整个网络结构,这并不总是理想的“,尤其是对于节点与连边规模非常巨大的网络,其计算成果也会较高,”有时,人们可能只想知道一个小区域内的社团,并希望避免分析整个事件的计算负担。更重要的是,在某些情况下,对整体网络的关注可能会导致有问题的结果。例如,模块度最大化返回的结果依赖于网络的总体大小,从而产生了所谓的分辨率限制,类似的限制也出现在其他方法中”,这一分辨率限制会导致全局算法(global algorithm)无法将相对小规模的社团有效检测出来。所以发展快速的局域算法(local algorithm)是社团划分未来重要的方向之一。
2. 新的社团检测算法——局域搜索算法
近期发表在 Communications Physics 上的这项工作提出了一种新的社团检测算法——局域搜索算法(Local Search,LS)。LS算法从局域优势(local dominance)的角度重新思考了社团的概念,其核心思想是网络中的节点会根据其邻居节点的连接度来决定自己的归属。不同于依赖全局信息的模块度优化算法和谱方法,不需要传统贪心算法和层次聚类方法的复杂优化过程,LS算法能够通过局域信息和局域广度优先搜索来快速识别社团结构。这种方法具有线性的时间复杂度,在无需计算节点间相似度的前提下,不仅能够揭示网络中的层级结构,识别社团中心,探测多尺度社团结构,还能够在噪声较大或数据不完整的情况下稳定工作,同时还能与向量数据聚类产生统一的联系与理解,并且能够取得很好的聚类效果。
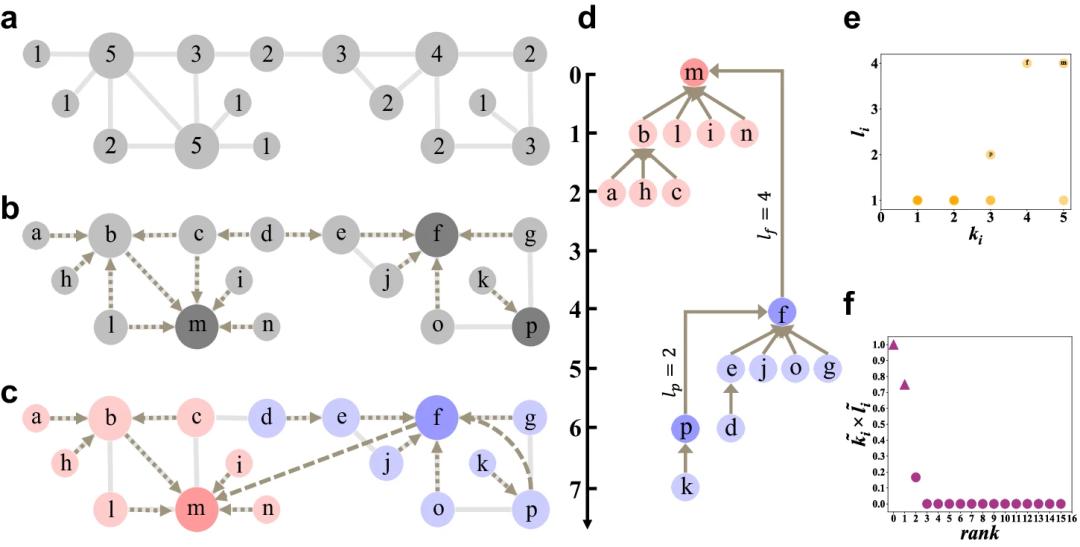
图1. 局域搜索(LS)算法的示意图。a 示例网络,其中节点上的数字和节点的大小表示节点的度;b 通过创建由有向边(虚线)指示的有向无环图(directed acyclic graphs,DAG)森林,构建局域优势关系,识别局域领导者(local leader)。c 局域广度优先搜索过程,从每个局域领导者开始,搜索直到遇到度数不小于当前节点的另一个局域领导者。d 由局域优势形成的相应树形结构。e 所有节点的度k和距离l的散点图。社团中心既有较大度值,也有较长距离。f 基于归一化度和归一化距离的乘积定量确定社团中心的决策图。
LS(Local Search)算法的基本步骤如下:
1. 计算每个节点的度值(这里是为了计算节点的影响力,完全可以使用其他网络中心性指标或者节点的属性值)
构建局域优势关系:
遍历网络中的每个节点,使每个节点指向度最大的邻居节点(而且需要这个最大的邻居节点比自己影响力更大才会指向,不然则不指向);如果有多个邻居的度相同,则随机选择其中一个。如果没有邻居大于或等于自己的度值,则该节点不会有出边。
识别局域领导者(Local Leader):
那些没有指向任何其他节点的节点被识别为局域领导者,它们是潜在的社团中心(参见图1b中的深灰色节点)。
局域广度优先搜索(Local Breadth-First Searching,LBFS):
从每个局域领导者开始执行局域广度优先搜索,以确定其在局域层次结构中的位置。搜索停止条件是遇到另一个度数不小于当前节点的其他局域领导者(图1c)。在LBFS过程中,记录局域领导者之间的最短路径长度。
确定社团中心、分配社团成员
根据节点的度和它们到最近局域领导者的距离,可以确定社团中心为图1e中右上角的节点;另外可以二者的乘积来更定量化地确定哪些节点是社团中心(图1d)。一旦社团中心确定,即可将社团标签沿之前构建的DAG中有向边的反方向传播给相应节点,完成社团划分。
作者在一些经典的合成基准网络(包括规则网络、Erdős-Rényi 随机网络、随机块模型SBM网络和 Ravasz-Barabási 层次网络模型)和真实基准网络(如 Zachary Karate Club、Cora、PubMed 等)上测试了LS算法的性能。结果显示,LS算法在多个标准基准测试中表现优异,尤其是在检测社团层次结构方面。与传统的社团检测方法相比,LS算法在保持高准确性的同时,显著提高了效率,例如在三十万节点、一百万条连边的大规模PubMed网络上LS的速度比现有经典的最快算法Louvain快近五倍!
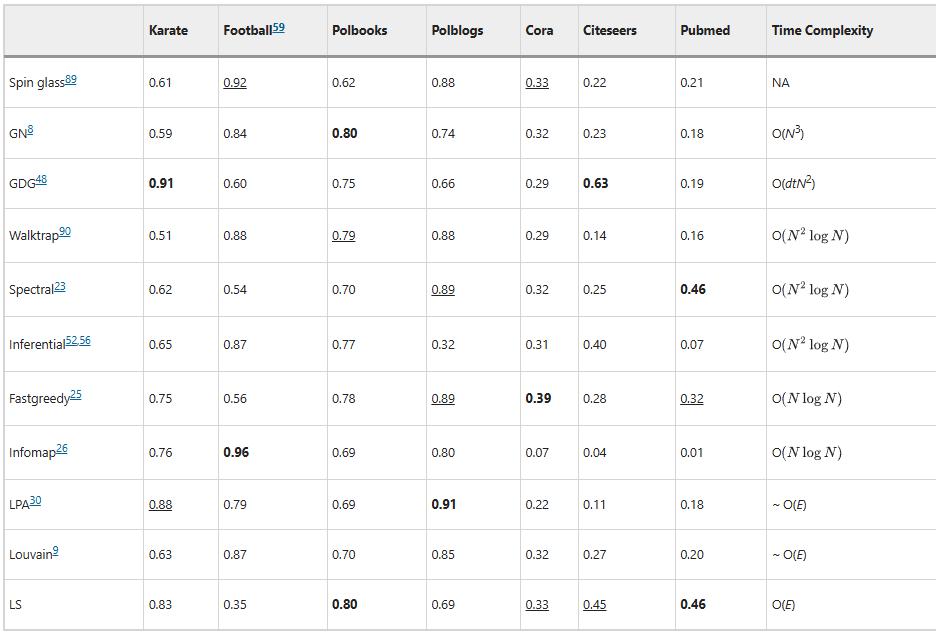
表1 带社团标签的真实网络上,LS算法与经典社团检测算法的比较。准确率比较采用F1-Score,F1-Score是机器学习中预测和地面真相标签之间的常见性能衡量标准。
3. 揭示城市空间交互模式
文章还将LS(Local Search)算法的应用扩展到了城市系统,作者通过分析大规模的手机信令数据,构建了城市中的流动性网络,旨在揭示城市中空间相互作用的结构。在城市流动性网络中,每个节点代表城市的一个区域,节点之间的边代表区域间的流动性,边的权重可以是人流量或其他流动性指标。
文章通过分析达喀尔(Dakar,塞内加尔共和国)、阿比让(Abidjan,科特迪瓦共和国)和北京三个城市的手机信令数据,使用LS算法识别城市中的社团结构,发现对于较小的城市达喀尔和阿比让,发生紧密交互的社团中的节点在空间上更加互相邻近,而在较大的城市,如北京,社团中的节点在空间上更加混合、在空间中的分布也更加不邻近。
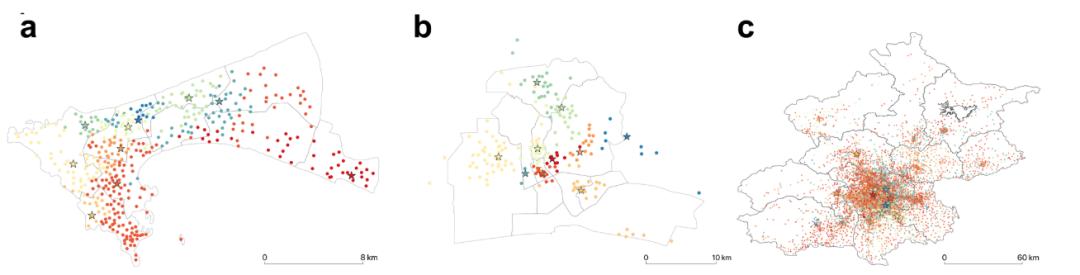
图2 局域搜索(LS)算法在移动流量网络上检测横跨大陆的三个多元化城市的社团结构。a 达喀尔,塞内加尔,非洲;b 阿比让,科特迪瓦,非洲;c 北京,中国,亚洲。
这些社团可能对应于具有紧密社会经济联系的区域,例如商业中心、居民区或工业区。通过识别这些社团,我们可以更好地理解城市内部的功能分区和空间组织,有助于揭示城市是否展现出多中心性(城市活动不仅仅集中在单一的中心区域,而是分散在多个社团中心)。这些社团中心通常是城市中的重要交互节点,如商业综合体、交通枢纽或文化设施。通过分析社团内部和社团之间的流动性,LS算法可以揭示城市空间交互的模式,从而为城市交通规划和基础设施建设提供数据支持。
4. 用于向量数据的聚类分析
尽管LS算法最初是为网络社团检测设计的,但其基于局域优势的概念同样适用于向量数据的聚类分析。在处理高维向量数据时,传统的聚类方法可能会遇到挑战,如维度灾难或对全局结构的依赖。LS算法这种基于局域信息的聚类方法,可能有助于克服这些挑战。
作者提出,可以通过将向量数据离散化为网络来应用LS算法。在这个过程中,向量被视为网络中的节点,而向量之间的距离或密度可以转化为网络中的边。为了将连续的向量空间离散化,作者采用了ϵ-球方法。这种方法通过设置一个距离阈值ϵ,将空间中所有彼此之间距离小于或等于ϵ的向量连接起来。这样,原本基于欧几里得距离的连续空间就被转换为基于局域邻接的网络结构。每一个ϵ值都会对应一个构建出来的网络,当ϵ从0不断增大的过程中,网络的最大连通子图(Giant Connected Component)会发生相变,在这样的相变点附近停下,在对应的网络结构(图3ae)上应用LS算法通常都能得到很好的效果(图3bf)。
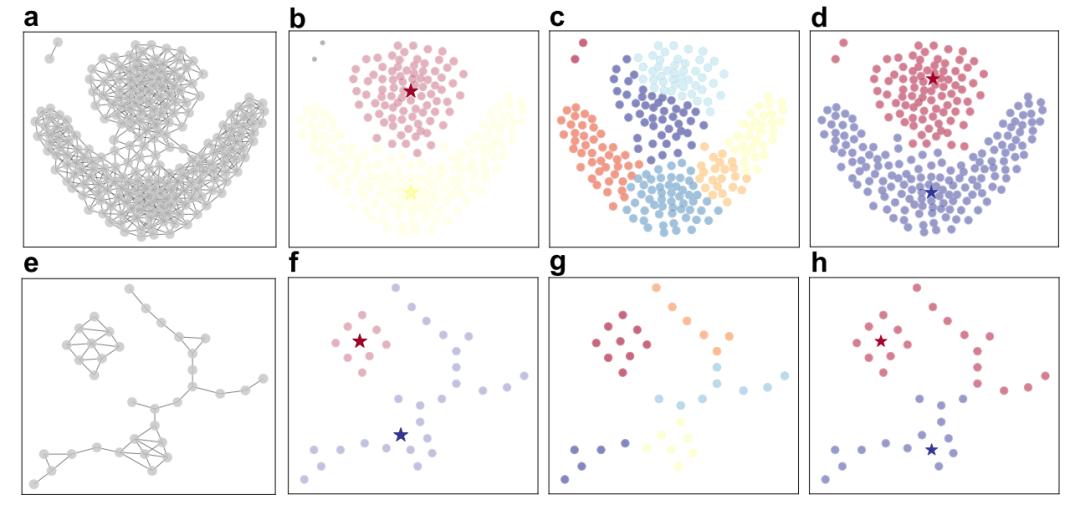
图3 对二维基准矢量数据的局域搜索(LS)、Louvain算法和基于密度和距离的算法(density and distance based,DDB)的聚类性能进行了比较。a/e 表示使用ϵ-Ball方法由矢量数据构建的网络;b/f LS方法的划分结果;c/g Louvain方法的划分结果;d/h 基于密度和距离的算法的划分结果。
图3对比了LS算法、Louvain 算法和2014年在 Science 上提出的密度-距离聚类算法(density and distance based algorithm, DDB)[1] 在二维基准向量数据上的聚类性能。图中显示了由 ϵ-球方法构建的网络,以及三种算法的聚类结果。LS算法能够正确识别出与常见共识一致的聚类,而 Louvain 算法倾向于产生更小且更分散的聚类。DDB算法在大多数基准数据上提供了正确的聚类,但在存在低密度流形的情况下可能会失败。
[1] Rodriguez, A. & Laio, A. Clustering by fast search and find of density peaks. Science 344, 1492–1496 (2014).
此外,LS算法还展现出了良好的鲁棒性。即使在网络结构受到随机噪声干扰或数据缺失的情况下,它依然能够准确地识别出社团结构。这一点在实际应用中尤为重要,因为现实网络往往充满了不确定性和不完整性。随着网络科学和数据科学的快速发展,社团检测技术的应用前景越来越广阔。LS算法的提出,为社团检测的概念提供了新的视角和工具。未来,我们期待看到更多像LS这样的创新方法,它们将帮助我们更深入地理解网络的内在结构,挖掘网络数据的潜力,为社会的发展带来新的动能。
LS算法的Python源代码:https://github.com/UrbanNet-Lab/LS_for_CommunityDetection_and_Clustering
LS算法即将被加入到Easy-Graph库中(https://github.com/easy-graph/Easy-Graph),Easy-Graph库是由复旦大学陈阳副教授领衔的复杂网络算法库,其执行效率比igraph等各类常见库都要更高。
原标题:《全新复杂网络社团划分Local Search算法,效率超经典最快算法5倍!》



